Designing for beginners
in a beginner industry.
Foundational research on the experience of building AI agents, revealing that even top engineering teams are beginners at it, and reshaping the product strategy around that.
TL;DR
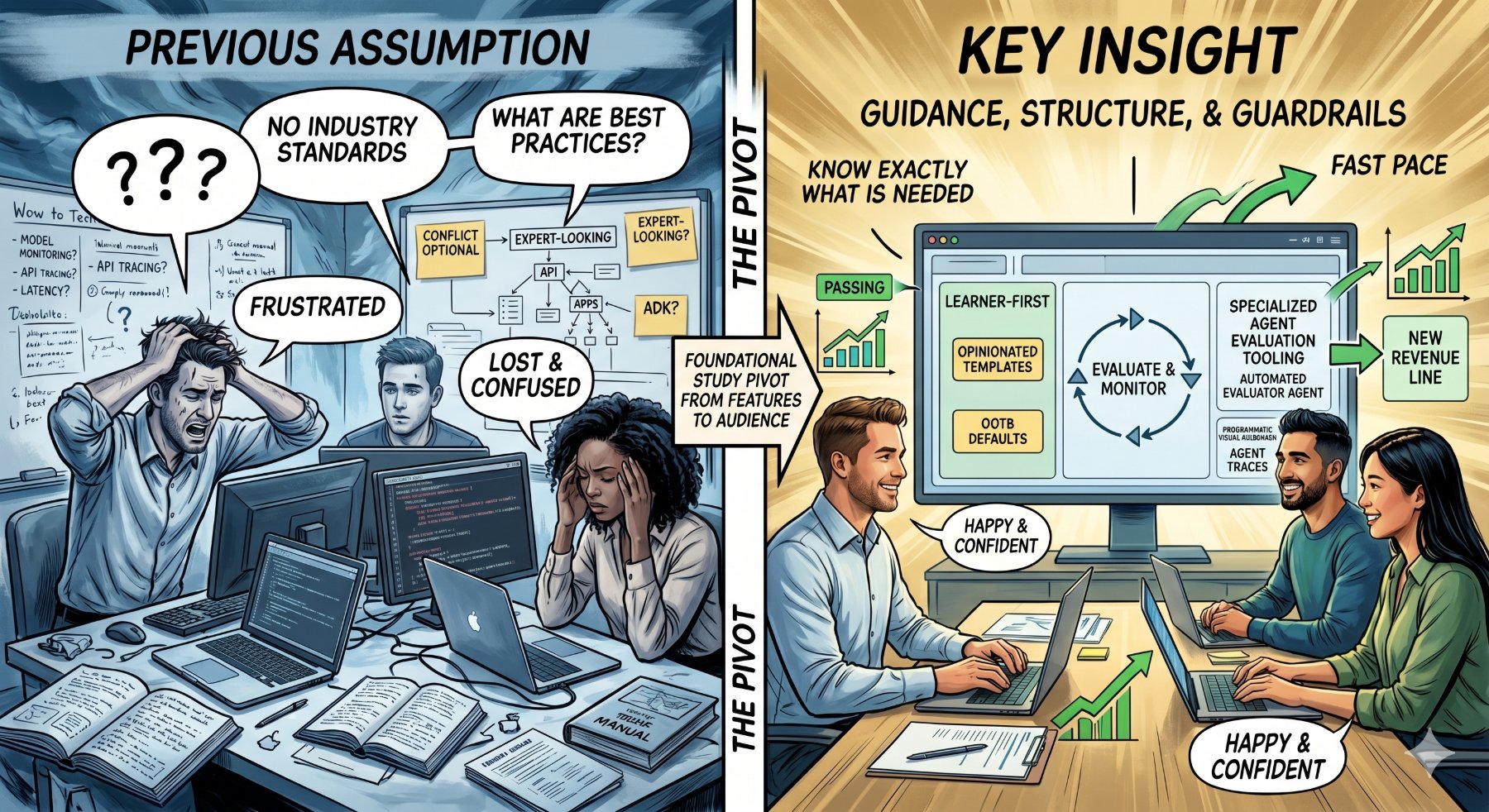
The team knew how to support observability for agents already running in production, but not for agents still under development, even though earlier research and customer calls had shown demand for it. I led a foundational study at top companies to map how teams actually build an agent, step by step. The finding: building agents is still new territory even at the most sophisticated companies, with no shared industry practices and a real hunger for purpose-built tools. That reshaped the product into a beginner-friendly tool with out-of-the-box dashboards and templates, and opened a new revenue stream for Google Cloud: specialized tooling for evaluating how well an agent performs.
Systems map
From a feature-scoping question to a market opportunity
The original framing was a feature question: what observability does someone building an agent need? I pushed to widen the scope before committing to features. A foundational study at top companies revealed something the product team's hypothesis hadn't accounted for: even sophisticated engineering teams are beginners at building agents, because the whole industry still is. That changed the question from “which features” to “which audience.” Designing for beginners in a beginner industry is a completely different product than designing for experts.
- Evaluation is the wall: Teams struggled with the basics of evaluation: choosing the right underlying model, judging whether an output was good enough, and measuring quality in any rigorous way. Most fell back on manual, ad-hoc checks.
- Observability disappears once an agent goes live: The visibility teams leaned on while developing an agent largely fell away once it moved to a live environment, leaving them to troubleshoot a multi-step reasoning flow by hand.
- No shared standards: With no common industry approach to building, evaluating, and observing agents, teams reinvented their own path each time; slow, inconsistent, and hard to repeat or hand off.
The clearest unmet need across interviews was purpose-built tooling to evaluate agents rigorously rather than by hand. That demand, plus the absence of any standard way to do it, is exactly the open space that turned a feature study into a new revenue stream.
What I almost missed
What I almost missed
I had built the study to over-represent senior AI engineers at top companies (the conventional sample for foundational research on a developer tool). Three interviews in, I noticed something off: even staff engineers at sophisticated companies were describing their agent-building workflow in tentative, exploratory language. They weren't experts. No one is, yet. If I had read that as “we need stronger participants” I'd have missed the finding. Instead, I treated the tentativeness itself as the data, and the study became a map of where the entire industry is, not just our sample. That reframe is what surfaced the beginner-first product strategy.
Every study gets a deliberate falsification pass before write-up: a structured hunt for the strongest evidence that the conclusion is wrong.